자바스크립트에서 데이터 타입(Data Type)은 기본형과 참조형으로 크게 두 가지로 분류된다. 각 데이터 타입에 대한 메모리 할당 순서와 어떤 차이점이 있는지 살펴보고자 한다.
기본형 타입(Primitive Type)
- 원시 타입이라고도 한다. 원시 타입의 변수들은 데이터 복사가 일어날 때, 메모리 공간을 새로 확보하여 독립적인 값을 저장한다.
null을 제외한 모든 기본 타입은 typeof연산자로 테스트가 가능하다.- typeof null은 object를 반환한다. 때문에 == null을 테스트해야 한다.
- 기본형 타입에는 총 6가지 타입이 존재한다.
- Number
- String
- Boolean
- null
- undefined
- Symbol
- Symbol은 ES6에서 추가된 타입이다.
참조형 타입(Reference Type)
- 참조 타입은 메모리에 직접 접근이 아닌, 메모리의 위치(주소)에 대한 간접적인 참조를 통해 메모리에 접근하는 데이터 타입이다.
- Object(객체)는 참조 타입이다.
- 참조타입은 다음과 같다.
- Array
- Function
- Set/WeakSet
- Map/WeakMap 등
- 참조타입은 다음과 같다.
👩🏫 Javascript의 메모리 구조
JS에서 메모리는 Stake Memory와 Heap Memory로 구분된다. 각 타입별 메모리가 할당되는 과정을 확인하기 전, 간단하게만 짚고 넘어가자!💡 Stack Memory
스택 메모리는 지역 변수와 함수 호출 시 생성되는 변수들을 저장하는 영역이다. 변수와 함께 기본형 데이터를 저장할 수 있으며 정적으로 할당한다.💡 Heap Memory
*힙 메모리는 프로그램에서 동적으로 할당된 메모리를 관리하는데 사용되는 영역이다. 이런 동적 할당은 프로그램에서 사용되는 데이터의 크기를 미리 예측하기 어려울 때 사용된다. 힙 메모리는 스택과 달리 메모리 블록을 계속해서 할당하거나 해제할 수 있기 때문에, 메모리 누수(Memory Leak)가 발생하기 쉽다. 메모리 누수란, 할당된 메모리를 해제하지 않은 채로 프로그램이 종료되거나, 해당 메모리를 더 이상 사용하지 않을 때 발생한다.
기본형 타입의 데이터 할당 순서
다음과 같은 코드가 있다고 가정했을 때, 기본형 타입의 데이터 할당 과정 순서를 알아보기로 한다.
var a;
a = "abc";
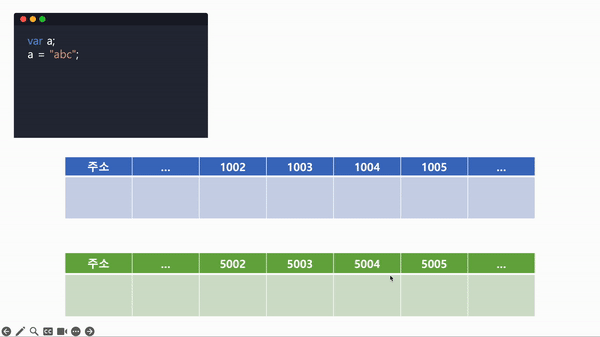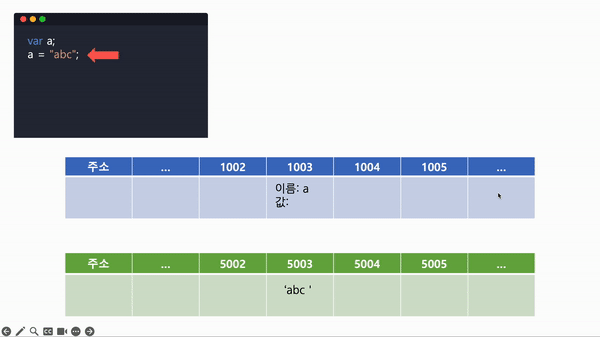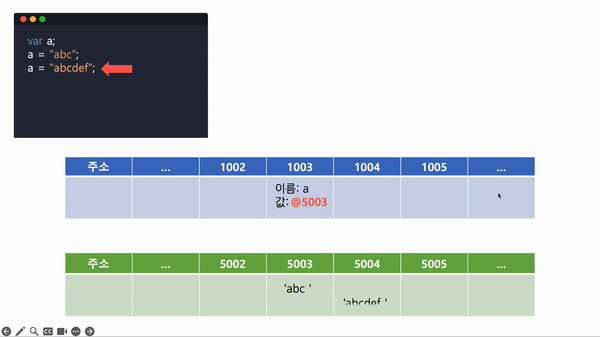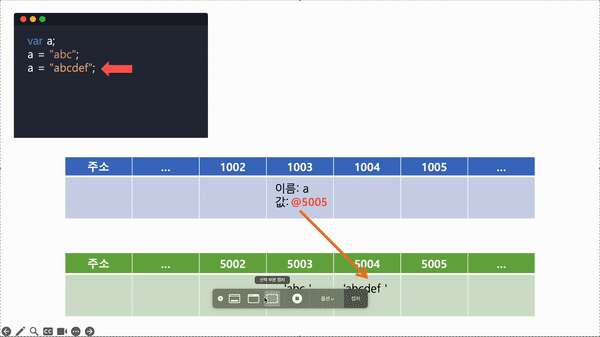
a = "abcdef";- a를 선언해 메모리에 담길 공간을 미리 확보한다.
- a에 'abc'를 대입하므로, 또 다른 비어있는 메모리 공간에 'abc'라는 값을 저장한다.
- a에 값을 대입해야하므로, 변수 a를 찾아 값이 들어있는 주소들을 검색하다가 식별자가 a인 주소를 찾아 대입해주어야 할 값의 메모리 주소를 넣어준다.
- 다시 a에 'abcdef'를 대입해야 하므로, 다시 비어있는 메모리에 'abcdef'를 저장하고, 식별자가 a인 주소를 찾아 'abcdef' 값의 메모리 주소를 저장한다.
아래 사진에서 해당 순서를 시각적으로 확인할 수 있다.
👩🏫 원시 타입은 불변성(immutable)을 가지고 있다.
Javascript에서 원시 타입은 변수가 할당될 때, 메모리의 고정 크기로 원시 값을 저장하고 해당 저장된 값을 변수가 직접적으로 가리키는 형태를 띈다. 또한 값이 절대 변하지 않는 불변성을 갖고있기 때문에 재 할당 시 기존 값이 변하는 것이 아니라 새로운 메모리 공간에 재 할당한 값이 저장되고 변수가 가리키는 메모리가 달라지는 것이다.
참조형 타입의 데이터 할당 순서
다음과 같은 코드가 있다고 가정했을 때, 참조형 타입의 데이터 할당 과정 순서를 알아보기로 한다.
var obj = {
a: 1,
b: 'bbb'
};
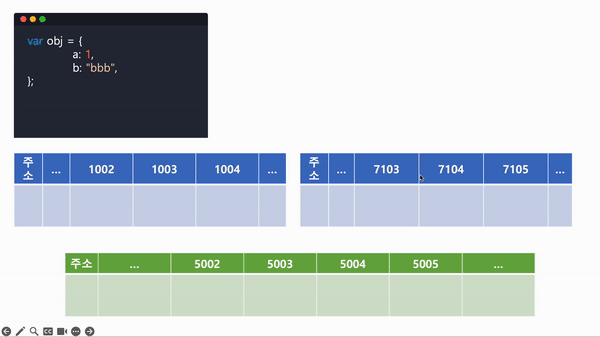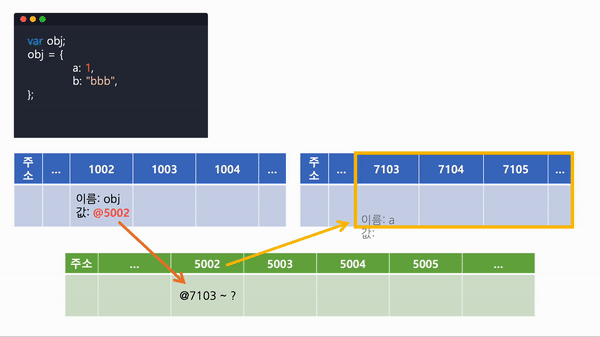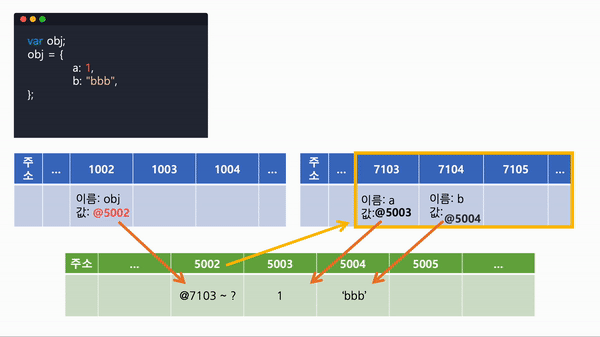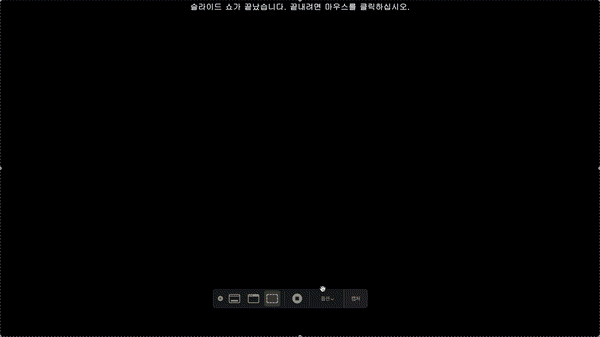
obj.a = 2;- 선언과 동시에 값이 할당된 obj는 컴퓨터가 읽었을 때, var obj; 로 선언을 먼저 하고, obj = {...};로 값을 대입하게 된다.
- obj를 선언해 비어있는 임의의 공간에 obj를 할당한다.
- 메모리 구조 공간에는 한 메모리에 하나의 값만 넣을 수 있으므로, 객체의 값을 담을 메모리 공간을 할당하고 할당된 주소를 가리키는 메모리를 obj의 값으로 가리킨다. (따라서 객체의 값을 담을 메모리를 가리키고있는 메모리 @5002를 가리킨다.)
- 객체의 값을 하나씩 선언하고 값을 저장, 참조한다.
아래 사진에서 해당 순서를 시각적으로 확인할 수 있다.
중첩 객체의 데이터 할당 기본 순서
var obj = {
x: 3,
arr: [3, 4],
};중첩 객체는 참조형 데이터 할당과 비슷하게 진행된다. obj의 메모리 공간을 할당하고, obj의 값을 가리키는 주소인 @5002를 값으로 불러온다.
5002는 객체의 값을 저장하기 위해서 프로퍼티에 값을 할당해줄 공간을 @7103 ~ ? 까지 확보를 하고 그 안에 x의 값과 arr의 값을 담는다. 여기서 x의 값은 @5003에 저장된 3을 가져온다.arr은 배열이므로 이 또한 참조형 데이터이다. 배열은 가변적인 데이터 그룹으로, 메모리 공간을 객체 obj와 동일하게 여유롭게 확보한 후, 해당 메모리 안에 값을 저장한다.
지금의 경우 메모리 공간을 @8104 ~ ?를 확보한 후, 8104에는 저장된 인덱스 0의 값을 불러오는데, 이미 메모리상에 3이라는 값이 저장되어있는 메모리가 있으므로, @5003의 값을 가져온다. 4의 값은 저장되어있는 것이 없으므로, @5004라는 새로운 메모리에 4라는 값을 불러와서 값을 저장한다.
| 주소 | ... | 1002 | 1003 | 1004 | ... |
| 이름: obj 값: @5002 |
| 주소 | ... | 5002 | 5003 | 5004 | 5005 | ... |
| @7103 ~ ? | 3 | @8104 ~ ? | 4 |
| 주소 | ... | 7103 | 7104 | 7105 | ... |
| 이름: x 값: @5003 |
이름: arr 값: @5004 |
| 주소 | ... | 8104 | 8105 | 8106 | ... |
| 이름: 0 값: @5003 |
이름: 1 값: @5005 |
참조카운트?
참조 카운트란, 참조하고 있는 대상을 숫자로 표현하는 것을 말한다.
var obj = {
x: 3,
arr: [3, 4],
};
obj.arr = "str";여기서 obj.arr의 값이 'str'로 변경된다면 우선 'str'이라는 값을 새롭게 메모리에 저장하게된다.
이렇게 저장된 값을 @7104가 가리키는 값으로 변경하게 되고 기존에 배열의 값을 가리키던 @5004를 가리키는 대상이 사리지게 된다. 이때, 참조 카운트가 0이 되었다고 표현한다.
참조 카운트가 0인 메모리는 가비지 컬렉터의 수집 대상이 되어 저장된 값이 사라지게 된다. 때문에 참조를 받지 못하는 @5004와 @5004가 참조하고 있던 @8104 ~ ?까지 연쇄적으로 가비지 컬렉터의 수집대상이 되어 같이 사라지게 된다.
| 주소 | ... | 1002 | 1003 | 1004 | ... |
| 이름: obj 값: @5002 |
| 주소 | ... | 5002 | 5003 | 5004 | 5005 | 5006 | ... |
| @7103 ~ ? | 3 | GB @8104 ~ ? |
4 | 'str' |
| 주소 | ... | 7103 | 7104 | 7105 | ... |
| 이름: x 값: @5003 |
이름: arr 값: @5006 |
| 주소 | ... | 8104 | 8105 | 8106 | ... |
| GB 이름: 0 값: @5003 |
GB 이름: 1 값: @5005 |
값을 직접 저장하는 방식과 값의 주소를 저장하는 방식의 차이점
값을 직접 저장
- 데이터 할당시에는 빠름
- 비교에 비용이 많이 듬
- 메모리 낭비가 심함
| 주소 | ... | 1002 | 1003 | 1004 | ... |
| 이름: x 값: 대충 세어봐도 30바이트가 넘는 문자열 |
| 주소 | ... | 5002 | 5003 | 5004 | ... |
| 이름: o 값: 대충 세어봐도 30바이트가 넘는 문자열 |
💡 약 30 * x byte의 메모리 필요
값의 주소를 저장
- 데이터 할당시에는 느림
- 비교에 비용이 들지 않음
- 메모리 낭비 최소화
| 주소 | ... | 1002 | 1003 | 1004 | ... |
| 이름: o 값: @1003 |
대충 세어봐도 30바이트가 넘는 문자열 |
| 주소 | ... | 5002 | 5003 | 5004 | ... |
| 이름: o 값: @1003 |
💡 약 30 + X byte의 메모리 필요
변수 복사
var a = 10;
var b = a;
var obj1 = { c: 10, d: "ddd" };
var obj2 = obj1;변수 a는 10의 값이 저장되어 있는 @5002의 값을 가리킨다. 변수 b는 a의 값을 대입하므로 a의 값이 저장되어있는 @5002를 값으로 가리킨다.
변수 obj1은 객체를 값으로 저장하므로 충분한 메모리를 할당하고 그 메모리를 할당한 주소인 @5003을 가리킨다. 할당된 메모리인 @7103에 c를 선언하고 c의 값은 10이므로, 미리 10이라는 값이 저장되어있던 주소인 @5002를 값으로 가리킨다. d의 값은 문자열 'ddd'이므로 저장된 값이 없으니 빈 메모리에 새롭게 저장하여 저장된 주소인 @5004를 가리키게 된다. 변수 obj2는 obj1의 값을 대입하므로 obj1의 값이 저장되어 있는 @5003을 값으로 가리킨다.
| 주소 | ... | 1002 | 1003 | 1004 | 1005 | ... |
| 이름: a 값: @5002 |
이름: b 값: @5002 |
이름: obj1 값: @5003 |
이름: obj2 값: @5003 |
| 주소 | ... | 5002 | 5003 | 5004 | 5005 | ... |
| 10 | @7103 ~ ? | 'ddd' |
| 주소 | ... | 7103 | 7104 | 7105 | 7105 | ... |
| 이름: c 값: @5002 |
이름: d 값: @5004 |
기본형과 참조형의 차이점
- 기본형은 값을 직접 가리키고 있기 때문에 같은 값을 가리키고 있던 변수라도 값이 바뀌면 서로 가리키고 있는 주소가 달라지는 반면에,
참조형은 가리키고 있는 값에서 한 번 더 메모리를 할당하는 과정을 거치기 때문에, 객체의 값을 바꿨을 때는 여전히 두 변수 다 같은 객체를 가리키고 있는 것이다.
var a = 10;
var b = a;
var obj1 = { c: 10, d: "ddd" };
var obj2 = obj1;
b = 15;
obj2.c = 20;
| 주소 | ... | 1002 | 1003 | 1004 | 1005 | ... |
| 이름: a 값: @5002 |
이름: b 값: @5005 |
이름: obj1 값: @5003 |
이름: obj2 값: @5003 |
| 주소 | ... | 5002 | 5003 | 5004 | 5005 | 5006 | ... |
| 10 | @7103 ~ ? | 'ddd' | 15 | 20 |
| 주소 | ... | 7103 | 7104 | 7105 | 7105 | ... |
| 이름: c 값: @5006 |
이름: d 값: @5004 |
[ 출처 ]
- 정재남, “코어 자바스크립트”, 인프런
- https://velog.io/@surim014/%EC%9B%B9%EC%9D%84-%EC%9B%80%EC%A7%81%EC%9D%B4%EB%8A%94-%EA%B7%BC%EC%9C%A1-JavaScript%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80-part.2
- https://velog.io/@nomadhash/Java-Script-%EA%B9%8A%EC%9D%80-%EB%B3%B5%EC%82%AC%EC%99%80-%EC%96%95%EC%9D%80-%EB%B3%B5%EC%82%AC
- https://developer.mozilla.org/ko/docs/Web/JavaScript/Data_structures
'개발일지 > JavaScript' 카테고리의 다른 글
| [Javascript] Callback_실행시점, 매개변수, this 제어권 위임 (0) | 2024.04.11 |
|---|---|
| [Javascript] ThisBinding_전역, 함수, 메서드, callback, 생성자 함수(new) 호출 시의 this / this 바인딩 명령어(call, apply, bind) (0) | 2024.04.05 |
| [Javascript] Math.pow(), Math.sqrt()_거듭제곱 메소드, 제곱근 메소드 (0) | 2023.09.15 |
| [Javascript] replace, replaceAll. 문자열에서 특정값 제거, 특정값 전부 제거 (0) | 2023.07.21 |
| [Javascript] String.search()_문자열 검색 메소드 (0) | 2023.07.20 |
